
What if you could use a component before it existed?
In the early days of programming, you wrote all the code yourself, save for the OS it ran on. A bit later, paid libraries became a viable business model ($500 to avoid implementing data grids yourself? Deal!). The final boss, or so we thought, was open-source: package repositories like npm, PyPi, Maven, etc. are now ubiquitous, and these days most apps are using hundreds of third-party packages.
But for the umpteenth time in just the last decade, the rules and practices around software supply chains are being rewritten. The pendulum is swinging back toward “owning” more of the code you ship. We see this in the shift in popularity from npm install’d component libraries to codebase-resident component marketplaces like shadcn. Meanwhile, the growing number of supply chain attacks is making folks reconsider blindly bringing in new dependencies. Simultaneously, exponential improvements in AI software development mean even though you’re “owning” more of that code, you’re not necessarily writing it (or even reviewing it!) yourself. More and more folks are thinking, “maybe I just ask Claude to write it instead of installing another dependency”.
More code means more intent noise
Think about it—what percentage of your codebase represents “essential complexity”, encapsulating your design intention, business logic, etc, versus what percentage is incidental—boilerplate, rote data transformations, those extra <div>s to hack a layout, etc?
Written language on the other hand, offers an unbounded spectrum of intent signal and specificity. For example, depending on how much you care about the details, these two descriptions can represent the same thing:
- A React date range component
- A React date range component that lets users choose a range manually or pick from a list of preset ranges like “this year”, “this month”, or “last month”.
For a given module, if you have weak opinions—just say less. Strong opinions? Be as specific as you like! The only problem with natural language is, it’s ambiguous. At the end of the day, choices MUST be made if you’re compiling from natural language into working software, and at least for today, code is still the only way we know to “capture” those choices.
Maximizing intent in your codebase
Let’s take a brief detour and look at something we’ve all used for decades—deterministic code generation. Think of tools like ts-proto that generate TypeScript code from protobufs, or GraphQL codegen. There’s a reason it’s often a best practice to gitignore generated code, choosing instead to regenerate those files from checked-in source material as a build or postinstall step. The source material (the actual protobuf, or GraphQL schema, or whatnot) is the source of truth, and is high-intent. The generated code, full of boilerplate, less so. The reason you’re able to gitignore generated code is determinism: you will predictably get the same output if the input (including tool versions) is the same—generated code is just a cache.
Generated code is just a cache
You don’t get the same predictability when compiling/prompting “A React date range component”—you’re almost certainly going to get a slightly different implementation every time. However, you can still “lock in” the decisions by thinking of AI-generated code as a kind of lockfile—one that doesn’t change so long as the source of truth doesn’t change:
| Source of truth | Lockfile |
|---|---|
| package.json | package-lock.json |
| requirements.in | requirements.txt |
| Natural language prompt/spec | Generated code |
Credit: GitHub Agentic Workflows has a similar concept, turning markdown into a github action (.lock.yml file)
For AI code gen, the real magic can come when you check in BOTH the source of truth and generated code. The natural language spec fully captures your intent at an arbitrary specificity—all those strong opinions and hard requirements, but nothing more. The generated code deals with the rest, predictably.
Magic modules, an experiment
Now that code is cheap, could we reinvent the software supply chain… again?
- Need a component?
Write it yourself. - Need a component?
Find it on npm. - Need a component?
Prompt a coding agent. - Need a component? Just start using it.
We built a small experiment called Magic Modules that lets you play with these concepts with either a small React or Python CLI codebase. The React version bundles and runs entirely in the browser thanks to esbuild-wasm, and the Python version, including the agentic verification step, runs on Pyodide, with Xterm.js for interaction.
Need a component? Just start using it.
The idea in this experiment is that for a given module (e.g. a Python module file, or React component), you could decide to make it a “magic module,” meaning that its “source of truth” would be a spec. You don’t ever edit its code. Want to change it in some way? Change its spec.
Furthermore, we thought, “why not auto-generate the first version of that spec?” LLMs are quite good at inferring specs from usage, in the same way they can interpolate and extrapolate out business logic from e.g. unit tests.
So here’s the idea behind the Magic Modules experiment, which is available in both Python (CLI) and React (Web) flavors:
To change how the date picker works, just edit the spec:
Let’s take an example. Suppose you have an idea for a new UI that needs a date picker. Instead of npm install’ing a datepicker, you’d just type: <Magic.DatePicker value={value} onChange={setValue} /> in place and hit Save:
Figure 1. Building a datepicker just by typing Magic.DatePicker where we want to use it. Note: Sped-up video
When you hit Save, the editor saw you needed a DatePicker, inferred its props from the usage, spec’d it (creating a .magic.md file), and built it (into a hidden .magic.tsx file).
What was particularly interesting in our early explorations was the ability to decide on your abstractions and compose magic components:
<Magic.PulsatingGradientText color1="gold" color2="white">
<Magic.FormattedTimeUntil date="2027-01-01" />
</Magic.PulsatingGradientText>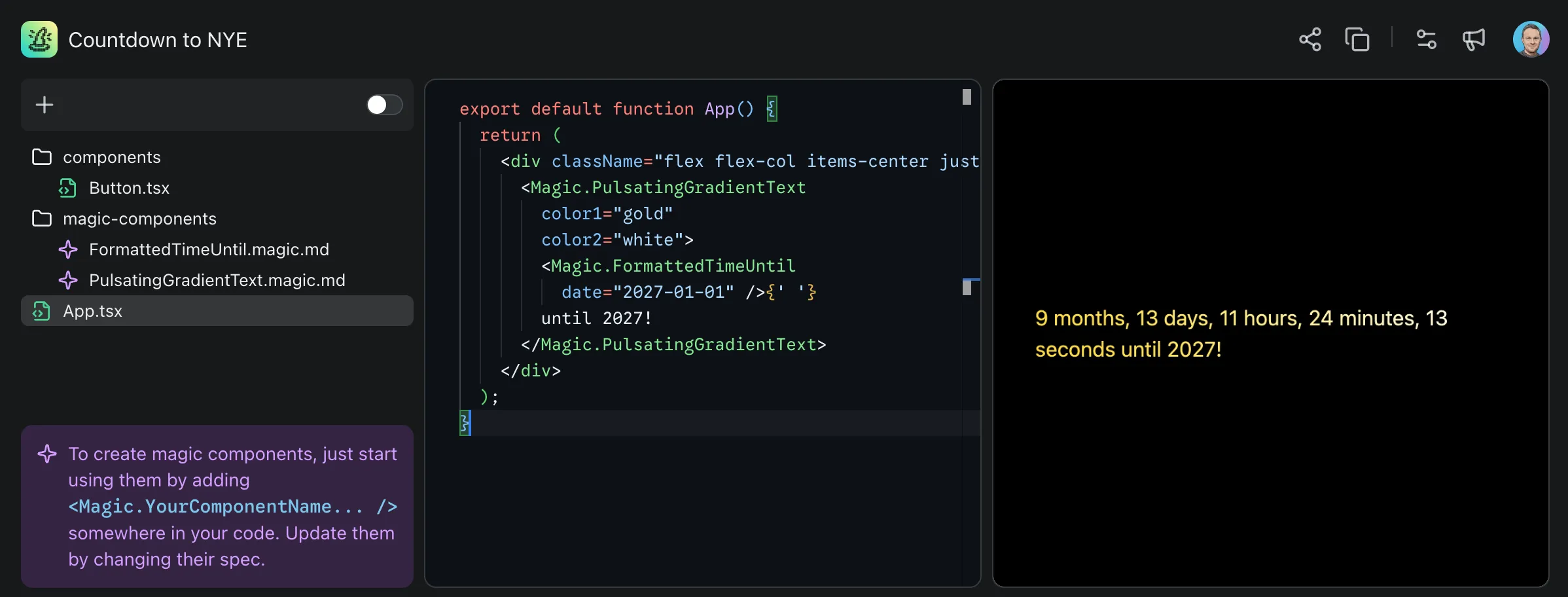
Figure 2. Composing magic components
Here, you as the user can decide you want distinct components for stylizing text and formatting it, and let the model infer from usage how to spec and implement them.
Spec and verification codifies intent
To refine your intent for a component, just edit the spec. This invalidates the module/component (because the hash changed) and rebuilds it:
Figure 3. Editing a magic module’s spec to change its behavior. Note: Sped-up video
We quickly realized in our exploration of the prototype that a spec isn’t quite enough—so we built agentic and static verification into the Python version of the demo:
Figure 4. Verifying a maze runner Python module agentically. Note: Sped-up video
Here, you can see a CLI-based maze game, with distinct modules for maze generation, display, gameplay, and automatic solving. The spec for the gameplay (maze_runner.py) includes an agentic verifier that runs a simple agent with keyboard() and read_display() tools and a “solve a randomly generated maze” objective.
A future version of this experiment would automatically run verifications when modules gets invalidated (rebuilt), providing feedback to the coding agent much like traditional test suites do today.
Delineated code ownership
A fascinating side effect of a system like this is it’s now clear who owns what. AI “owns” the magic module implementations; you can almost avoid looking at the code entirely, especially if you have static and agentic vulnerability scanning and other analytical processes in place. On the other hand, you “own” the modules that aren’t magic, along with the specification and requirements for the magic modules, which can again be written in an arbitrary level of detail.
Over time, you can “hand off” modules you don’t want to own to AI by making them magic modules. And vice versa: you can “take over” or “eject” modules from AI ownership by renaming them.
Over time, you can “hand off” modules you don’t want to own to AI
Challenges with this approach
A major downside is that low-specificity specs yield unstable, overly elastic modules. Even at temperature 0, you could get wildly different modules each time the cache invalidates from even the tiniest changes to the spec. A future exploration could tackle this as a compression problem, identifying the smallest mix of code, natural language, and tests that yield indistinguishably reproducible outputs (even across models).
Furthermore, while using coding agents introduces some volatility in your app code, magic modules push that volatility deeper along the software supply chain, in a sense “inverting the pyramid of stability” (to quote our colleague Adam Tait), drastically raising the stakes on solving for spec ↔ output lossiness.
What’s next
Coding agents are nearly ubiquitous and, at least with the current crop, are rapidly increasing codebase sizes. This early prototype just scratches the surface of one possible way to begin wrangling codebase complexity, by codifying source of truth in specs and verifications, rather than in the code itself.
There’s much, much more to explore here. For example, a bidirectional flow between spec and client code would be useful—healing the spec as usage patterns change or client code starts breaking. Stay tuned for more as we continue to explore the relationship between specs, verification, and code.
Want to try out the prototype? Check out the repo or reach out to @julesagent, David or Roman for some invite codes for your team to try the hosted prototype. And we’d love your feedback—does this problem and solution space resonate with you?