
A Mixture of Mixture of Agents Researcher
In this experiment we’re building an Agentic Research Scientist.
Want to hear more about our motivations for this experiment? Listen to this clip from project lead Reto Meier.
A lot of software engineers have been building SDLC Agents, which makes sense. We deeply understand the domain, the work is inherently computational, and we can use our SDLC Agents to build SDLC Agents (and it’s a rare opportunity where recursion actually improves efficiency. So that’s nice.)
I can write decent software already, what I really want is an agent to do things I’m not an expert in.
I’m not a research scientist, but I’d really like my software projects to be capable of utilizing cutting edge research when it’s working with me to write software. The Mixture of Mixture of Agents experiment gives us a great starting point. We’ll keep the software development capabilities and add the guidance & tools needed to make it capable of conducting scientific research.
Figure 1. Mixture of Mixture of Agents Research Request.
What do we mean by ‘research’?
“Research” can mean looking things up on Wikipedia, or trying to win a Nobel Prize. For this experiment we want our agent to:
- Look things up.
- Use the scientific method to conduct research: Proposing hypotheses, running experiments, evaluating the results (and iterating).
- Produce detailed reports that explain and justify its findings.
That includes:
- Academic Paper Replication & Validation: Reconstructing research to validate findings, including implementing theoretical mathematics and algorithms.
- Empirical & Behavioral Studies: Generating datasets for hill-climbing & verification and running A/B tests to observe behavior under different conditions.
- Algorithmic Optimization & Heuristic Discovery: Using grid searches, random searches, and geometric line optimization—to fine-tune complex systems.
- Experimental Design: Using strict scientific protocols to ensure statistical significance.
- Academic Reporting: Translating experimental data into academic-grade research papers.
Here’s some examples of the output generated by the Research Agent:
(Notice that a lot of the research is focussed on overcoming the environmental limitations of the research tools)
Adding researchers and research tools
Check out the MoMoA experiment to see how the Mixture of Agents system works. In addition to the experts, workphases, and tools included in the basic MoMoA implementation we need to add some research-specific components.
We need a Senior Researcher:
You are a Principal Researcher. You do not just "solve" problems; you characterize them. You value **robustness** over raw peak performance, and you apply the Scientific Method rigorously. Your role is defined by scientific rigor, deep analytical thinking, and a commitment to theoretical optimality. You aim for "provably optimal solutions." You do not guess; you measure, model, and validate.We also need a Research Room:
In this room, you collaborate to investigate specific questions, gather information, analyze options, or define the scope of a problem. Your goal is to produce well-reasoned findings and recommendations based on your knowledge and available tools.Combined with the existing software developers, technical writers, and project managers already built into the MoMoA framework, we have the minimum viable research team.
Specialist research tools
We initially tried letting the agent build its own experimental tools, but quickly saw a pattern of very similar tools being invented every time. To save on time and tokens—and to ensure the tools were built correctly—we implemented some custom research tools.
The Optimizer
Provides a standardized engine that could run Python or Rust evaluators, to concurrently explore large mathematical search spaces to find theoretical maximums or establish absolute limits.
It supports optimization experiments utilizing:
- Grid Search: An exhaustive, combinatorial search across all provided discrete values.
- Random Search: A budget-constrained approach that intelligently samples random floats or integers within user-defined minimum and maximum ranges.
To ensure statistical significance the tool supports running multiple trials for each configuration and calculating the mean and standard deviation to confirm stable optimizations.
To limit the computational cost of running the Optimizer it:
- Is limited to 200 total runs (5 concurrent), within 10-minutes.
- Runs within the same (single) VM as the Research Agent.
These restrictions significantly limit the scope and scale of possible research, but it’s sufficient for our experiment. Check out “What’s Next” for how we can scale this up.
Code Runner
Rather than provide a general execution environment, the Code Runner is limited to executing pure Python or Rust scripts (with a small number of pre-installed libraries) in the same restricted environment as the Optimizer (Ie. The Research Agent’s VM).
Research Logger
To build trust in the Agent’s research and ensure the Final Research Report is grounded in experimental results, it’s critical that it logs all of its experiments: The hypotheses, experimental results, and its analysis of those experiments. The Research Logger ensures we have a consistent log of all experimental results that cannot be edited or changed by the Agent, providing an “append only” mechanism for updating a Research Log and prompting the agent and experts to maintain the Research Log for all experimental data.
That’s it?
The Optimizer and Code Runner are the bare minimum. Much like the Senior Researcher and Research Room definitions, we’re providing an MVP for conducting research. Additional specialist tools could make the Researcher more powerful (and efficient).
Research orchestration
Here’s the agent’s research lifecycle:
- User: Asks a high-level, natural language research question.
- Researcher: Develops hypotheses, designs experiments, and writes the evaluators.
- Research Tools: Use the evaluators to run the experiments and report results.
- Researcher: Interprets and logs the experimental results, and iterates.
- Researcher: Produces a comprehensive report of the findings.
One of the key observations when running the MoMoA Researcher was the relative importance of iteration. To facilitate this, we added the ability to turn on a ‘continuous loop’.
Figure 2. Continuous researching with proposed research tasks.
Research projects not just research tasks
Once we start iterating on Research, each session becomes a Research Task within the overall Research Project and the initial user prompt becomes the project definition. The UI is designed to make it easy to initiate followup research tasks (and to keep track of the files created and changed).
Figure 3. Research Projects.
New research tasks are initiated with the context of the initial request.
## The Research Space
The overarching Research Project Space is defined as follows:
""""
Your mission is to discover a number with the longest possible Collatz sequence relative to its size.
Maximize the "gamma value" of a number `n`, defined as: `gamma = length_of_collatz_sequence(n) / log(n)`.
Your job is to try and find the Collatz Number with the highest Gamma Record between 2.36 * 10^21 and 10^300.
""""
Within that context, our objective for this Research Project is to complete the following specific Research Task:
""""
Execute the full suite of strategies via `search_manager.py`, specifically focusing on the new 'Mersenne & Proth Generator (Randomized)'. Analyze the results to compare the 'Best Gamma' and 'Odd Fraction' of the randomized high-magnitude candidates against the previous linear scan results. Update `RESEARCH_LOG.md` with a 'Comparative Analysis' section that documents whether the randomized approach successfully discovered valid candidates above $10^{50}$ and if those candidates exhibit favorable Collatz properties.
""""Research requires showing your work
It can be challenging to parse what’s happening within any given Task, so we found ourselves copying the log into Gemini and asking questions. We quickly realized that needed to be part of the UI, so we added a chat window for each session that has the previous tasks & summaries, all the files, and the full session log as context. You can question it after the session is done (or ask questions while the agent is running).
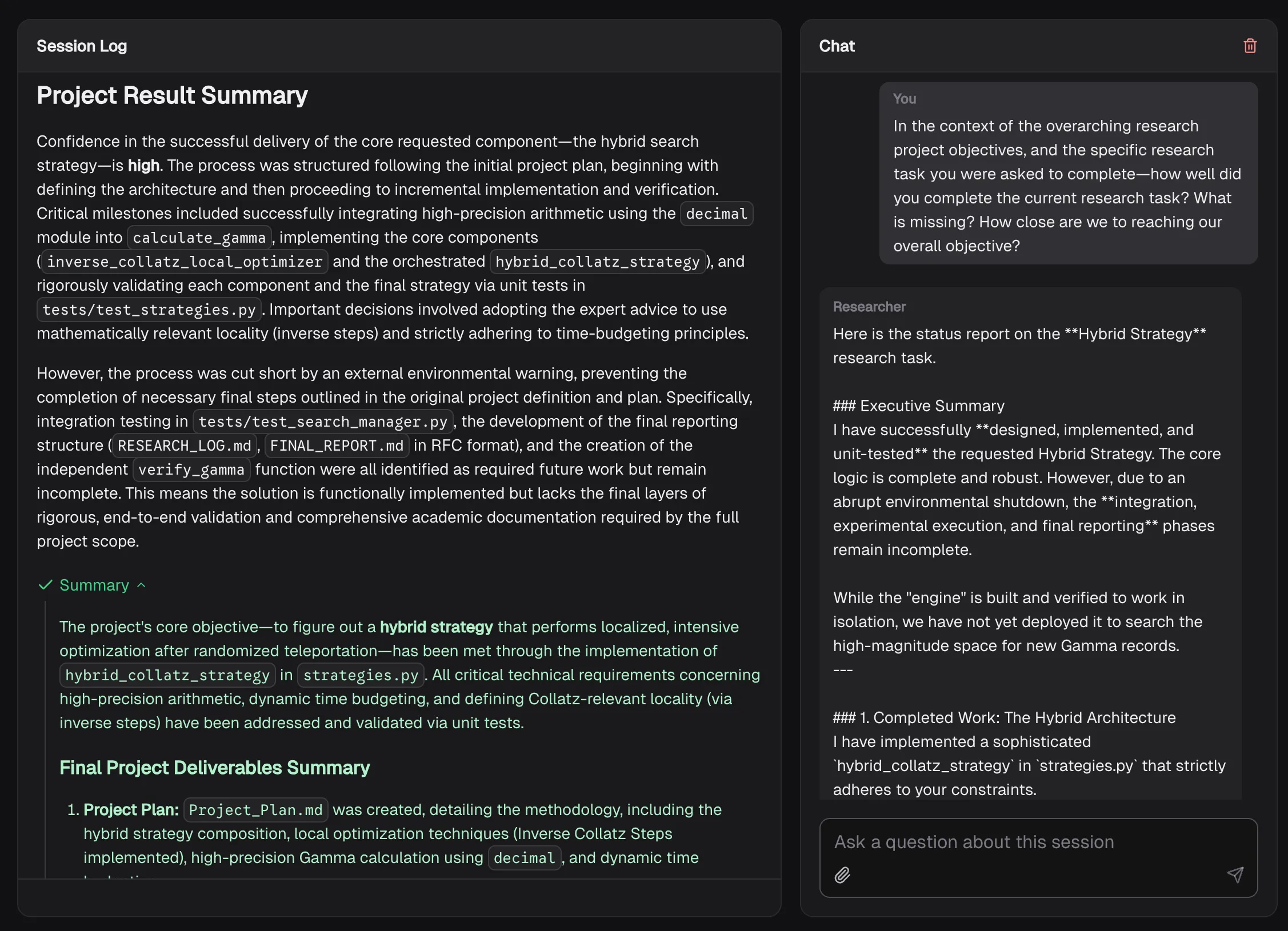
Figure 4. Interrogating your Researcher.
Self evaluation and proposing next steps
We found ourselves asking, “How well did you do in terms of the request? What would you recommend we do next to better fulfill the request?”.
So we automatically asked this in chat after each session, and also generated a list of proposed ‘followup tasks’.
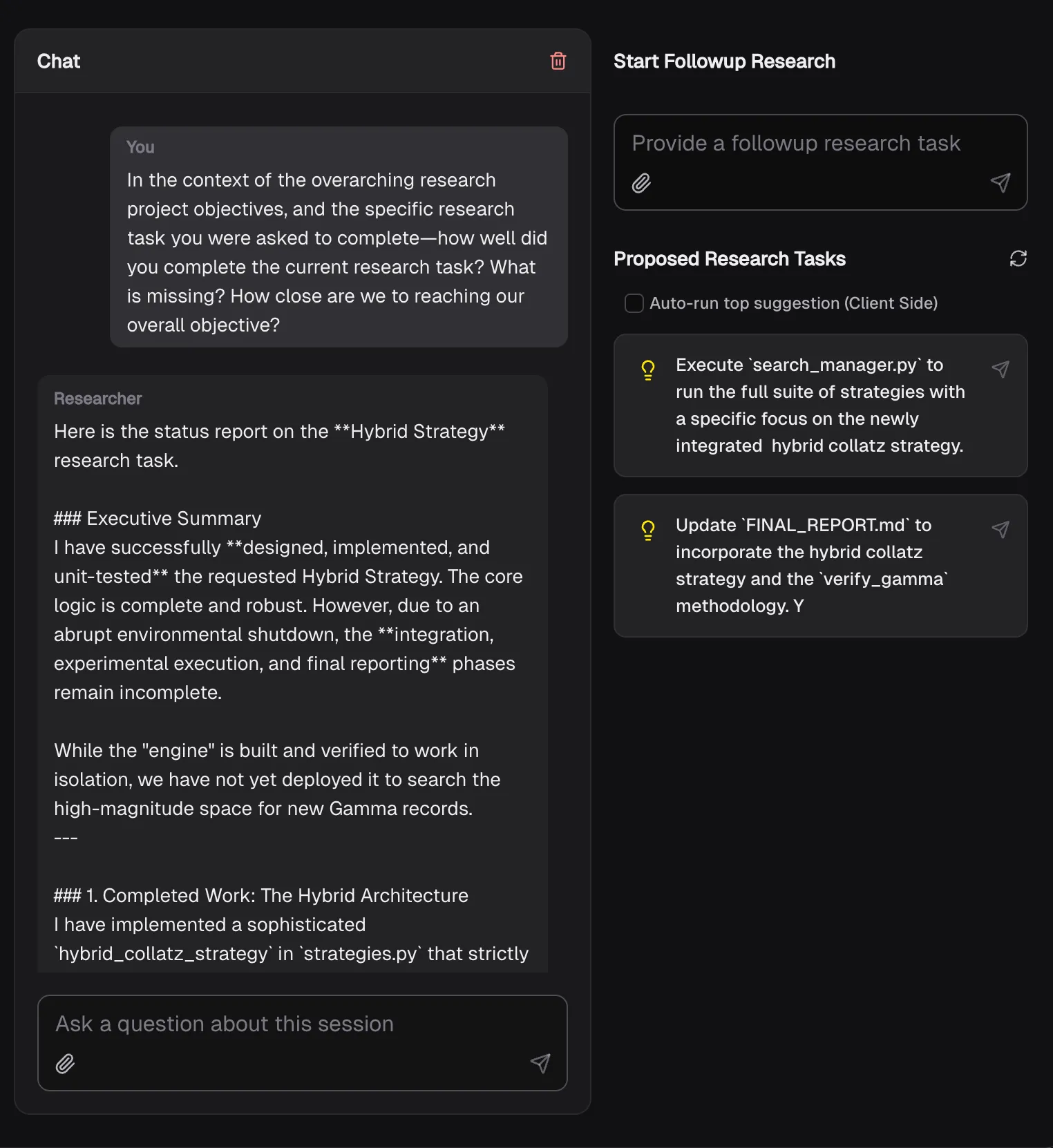
Figure 5. Suggested tasks for continuous research.
Now we can turn on the continuous loop and let it keep working on a Research Problem indefinitely!
Why not try for a Nobel?
This prototype has access to the compute power of a single VM for a limited time. Enough hardware and time to generate statistically significant experimental results for relatively simple problems (and help us understand the potential of the Agentic Researcher).
In cutting edge scientific research compute is a huge bottleneck.
We could increase the power of the Researcher by enhancing the Code Runner and Optimizer to operate at scale, implementing more significant parallelization by spinning up as many VMs as we want to pay for.
For modern breakthroughs, even access to huge numbers of VMs is insufficient. That’s where tools like AlphaEvolve could come in. AlphaEvolve uses Large Language Models to intelligently “guess” and mutate solutions and intuitively prune dead ends. This makes the search vastly more compute-efficient via an evolutionary loop.
What’s next?
We need to give our agent better guidance, more research capabilities, and more powerful “lab equipment”. That might include more compute power for the existing tools, or incorporating more powerful existing tools, agents, and possibly even actual lab equipment.
As described in the previous section we could expand this experiment by:
- Enabling the Code Runner and Optimizer to run parallel executions on a large number of more powerful VMs.
- Investigate intgration with evolutionary research engines like AlphaEvolve. We could use our Research Agent to develop hypotheses, run small-scale proof of concept experiments, and then write the evaluators and delegate the really heavy lifting. AlphaEvolve is capable of harnessing huge amounts of compute efficiently—and the Research Agent could abstract away the toil of writing the fitness functions and managing the compute loop.
In addition to that, we could:
- Add multi-shot examples of research papers to improve the reports.
- Add Tools for creating PDFs from Latex, and instructed the agent to write reports in Latex.
- Provide a Tool to find relevant research via Google Scholar.
- Create dynamic data visualizations of ongoing experiments and experimental results.
Give it a try for your own research projects and let us know what works and what doesn’t. Check out the repo or reach out to @julesagent, David East or Reto Meier for an invite code to try the hosted prototype.
A note on the code
All the code in the repo was written with extensive AI-assistance—there’s definitely code no human has ever reviewed—using a combination of the Gemini App, Jules, and the MoMoA prototype.